Matrix Vector Multiplication Cuda
Going for more quantity of multiplications than size of matrix. A block of BLOCK_SIZE x BLOCK_SIZE CUDA threads.

Word2vec Tutorial The Skip Gram Model Tutorial Machine Learning Learning
Sadayappan Department of Computer Science and Engineering Ohio State University Columbus OH 43210 yangxin srini sadaycseohiostateedu ABSTRACT Scaling up the sparse matrix-vector multiplication kernel.

Matrix vector multiplication cuda. This provides an understanding of the different sparse matrix storage formats and their impacts on performance. It was shown that its possible to. Our first example will follow the above suggested algorithm in a second example we are going to significantly simplify the low level memory manipulation required by CUDA using Thrust which aims to be a replacement for the C STL on GPU.
The formula used to calculate elements of d_P is. So I wounder how can I multiply a large no. Size BLOCK_SIZE.
Sparse Matrix-Vector Multiplication on CUDA - CUDA Programming and Performance - NVIDIA Developer Forums. Dim3 block BLOCK_SIZE BLOCK_SIZE. Perform CUDA matrix multiplication.
Size BLOCK_SIZE 1. The goal of this project is to create a fast and efficient matrix-vector multiplication kernel for GPU computing in CUDA C. Before wall_clock_time.
As an example the NVIDIA cuDNN library implements convolutions for neural networks using various flavors of matrix multiplication such as the classical formulation of direct convolution as a matrix product between image-to-column and filter datasets. Further there is a matrix multiplication example in the CUDA SDKexamples and CUDA ships with CUBLAS. I would like to know if anyone.
Matrix-Vector Multiplication Using Shared and Coalesced Memory Access. Dim size BLOCK_SIZE 0. In this paper we discuss data structures and algorithms for SpMV that are e ciently implemented on the CUDA platform for the ne-grained parallel architecture of the GPU.
Fast Sparse MatrixVector Multiplication on GPUs. A typical approach to this will be to create three arrays on CPU the host in CUDA terminology initialize them copy the arrays on GPU the device on CUDA terminology do the actual matrix multiplication on GPU and finally copy the result on CPU. It can be challenging to implement sparse matrix operations efficiently so I hope this report offers some.
Like this x0y0z0 1st vector. Mm_kernel a b result2 size. We now turn to the subject of implementing matrix multiplication on a CUDA-enabled graphicscard.
In the previous post weve discussed sparse matrix-vector multiplication. It ensures that extra threads do not do any work. Refer to vmppdf for a detailed paper describing the algorithms and testing suite.
Obvious way to implement our parallel matrix multiplication in CUDA is to let each thread do a vector-vector multiplication ie. In iterative methods for solving sparse linear systems and eigenvalue problems sparse matrix-vector multiplication SpMV is of singular importance in sparse linear algebra. Implications for Graph Mining Xintian Yang Srinivasan Parthasarathy P.
Dim3 grid dim dim. Im pleased to announce the release of our tech report Efficient Sparse Matrix-Vector Multiplication on CUDA. Of vectors each of one by a NN matrix to produce a new set of vectors.
Each element in C matrix will be calculated by a. A grid of CUDA thread blocks. I am doing all 4X4 matrices being multiplied by 4X1 vectors.
Matrix multiplication between a IxJ matrix d_M and JxK matrix d_N produces a matrix d_P with dimensions IxK. This is an implementation of a parallel sparse-matrix vector multiplication algorithm on the GPU. A search or a quick browse of recent CUDA questions will reveal at least three questions about this subject inlcuding code.
21 The CUDA Programming Model. Its not a very useful program but Im doing it to learn Cuda for a class so its kind of isolated in its usability. I yi alphaxi yi Invoke serial SAXPY kernel.
We will begin with a description of programming in CUDA then implement matrix mul-tiplication and then implement it in such a way that we take advantage of the faster sharedmemory on the GPU. Ive implemented matrix-vector multiplication as a CUDA kernel and am using the trust lib for scan I was wondering if CUBLAS would be much faster as its probably better optimised than my code but I dont really want to commit much time to learning CUBLAS if I dont know in advance that its going to be that much better. Hi there I currently use CUDA in LabVIEW for matrix multiplication as shown in the attachment the GPU is used to compute large amount of data.
Block Sparse Matrix-Vector Multiplication with CUDA. Examples of Cuda code 1 The dot product 2 Matrixvector multiplication 3 Sparse matrix multiplication 4 Global reduction Computing y ax y with a Serial Loop void saxpy_serialint n float alpha float x float y forint i 0. The one in the Cuda programming guide seems better for doing huge huge matrices once.
The above condition is written in the kernel.
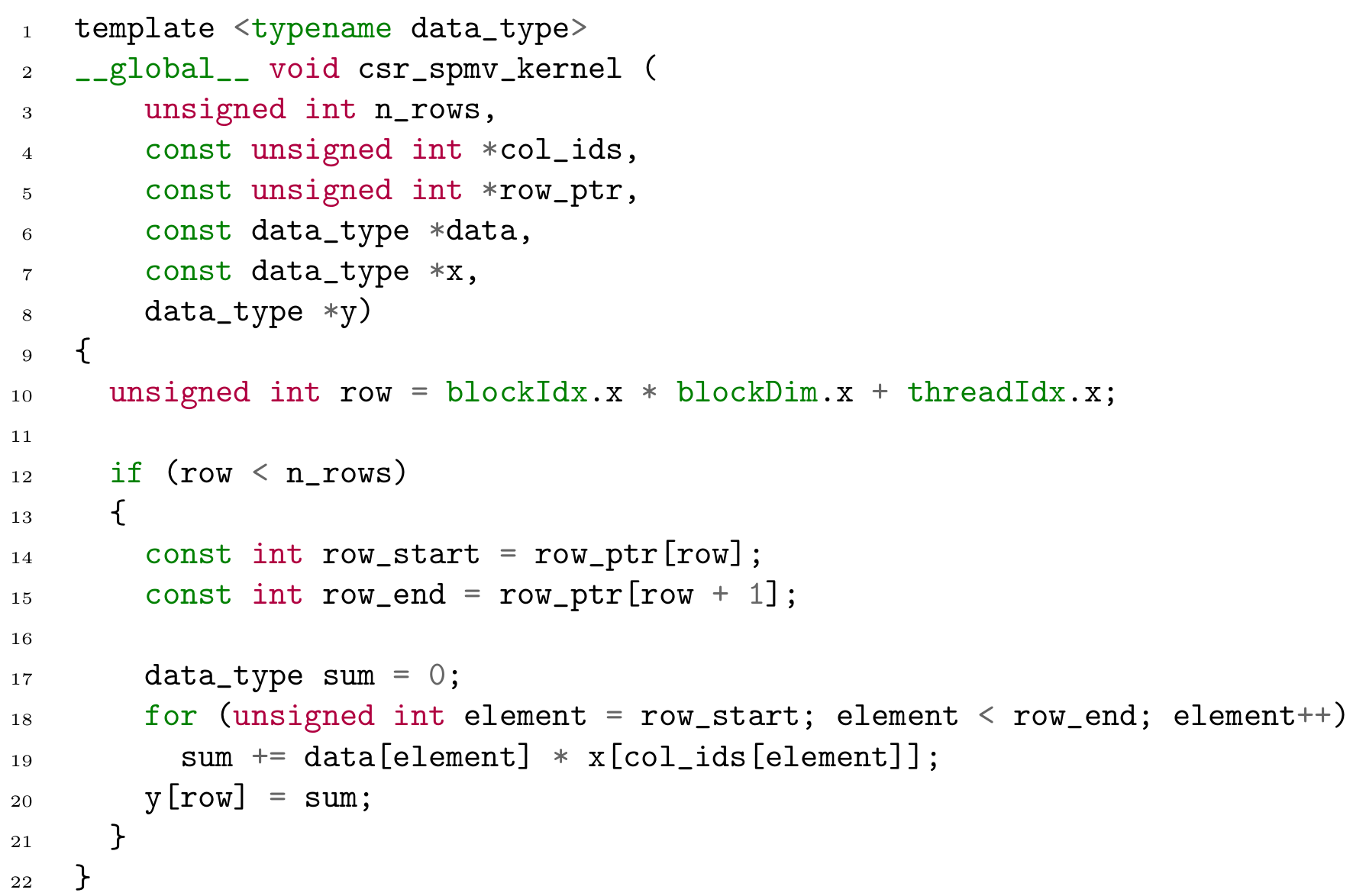
Sparse Matrix Vector Multiplication With Cuda By Georgii Evtushenko Analytics Vidhya Medium
Sparse Matrix Vector Multiplication With Cuda By Georgii Evtushenko Analytics Vidhya Medium
Sparse Matrix Vector Multiplication With Cuda By Georgii Evtushenko Analytics Vidhya Medium

Cuda Linear Algebra Library And Next Generation Ppt Video Online Download
Github Aneesh297 Sparse Matrix Vector Multiplication Spmv Using Cuda

Code Of Honour High Performance Matrix Vector Multiplication In Cuda C
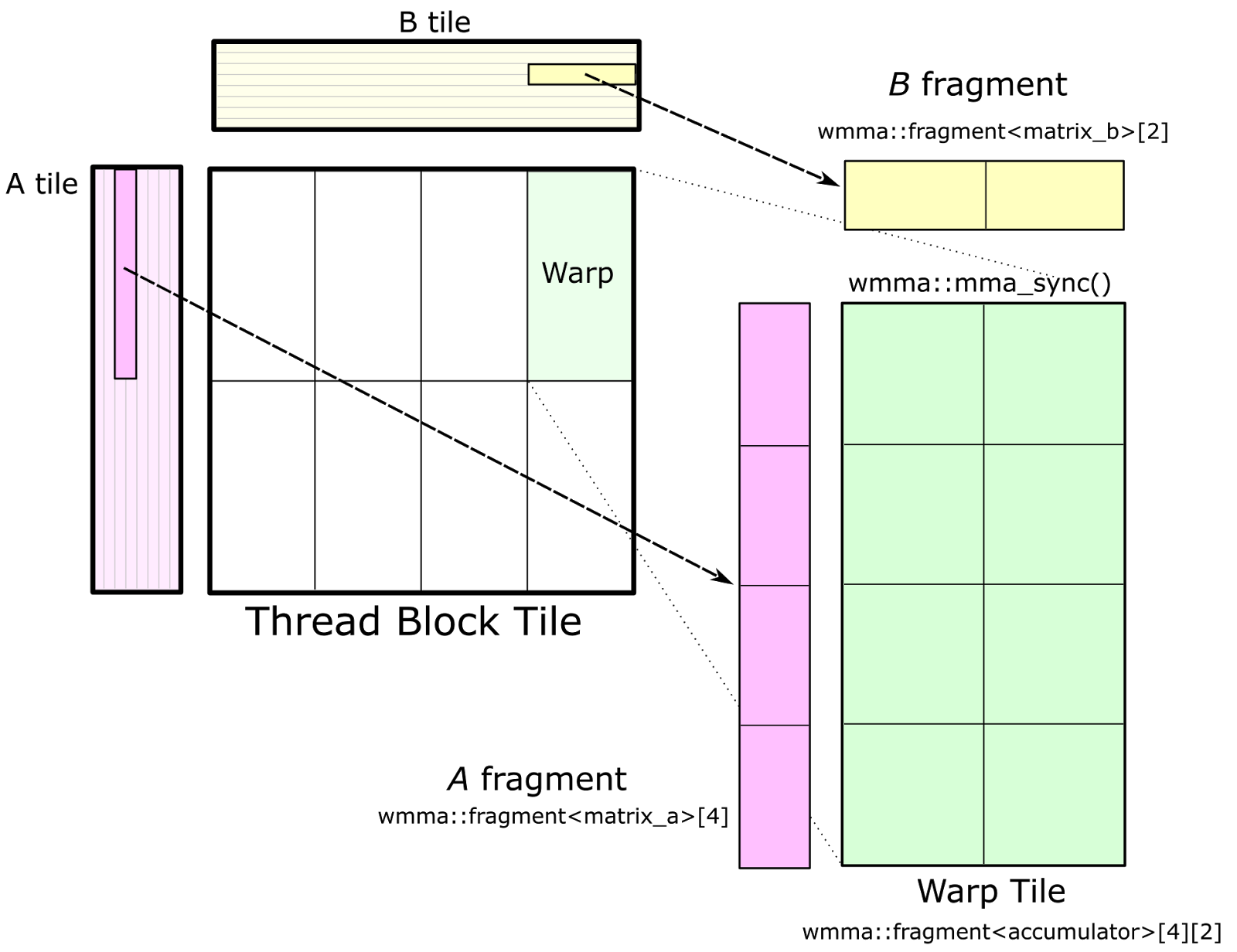
Cutlass Fast Linear Algebra In Cuda C Nvidia Developer Blog

Matrix Vector Multiplication In Cuda Benchmarking Performance Stack Overflow
Cuda Matrix Vector Multiplication Transpose Kernel Cu At Master Uysalere Cuda Matrix Vector Multiplication Github
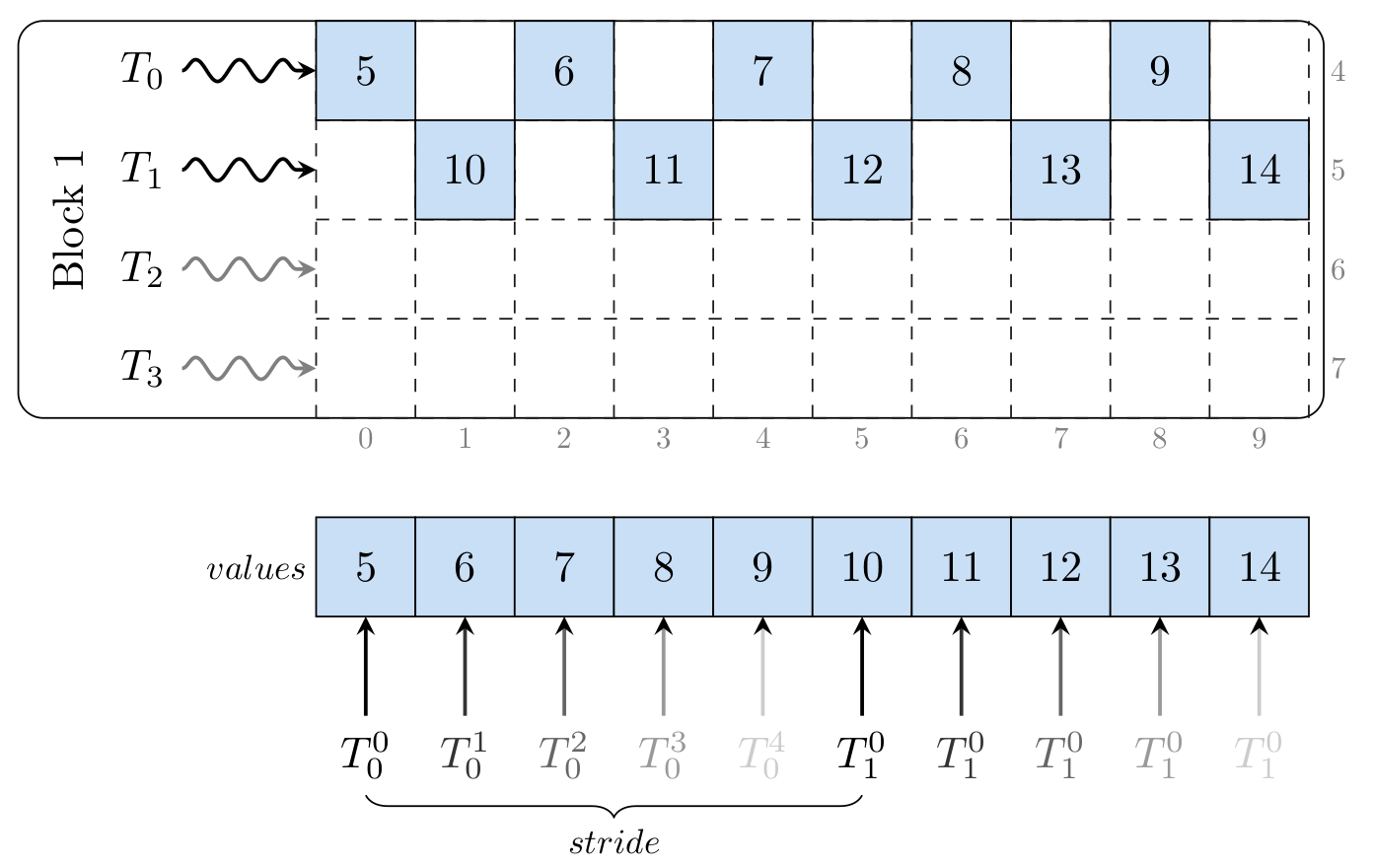
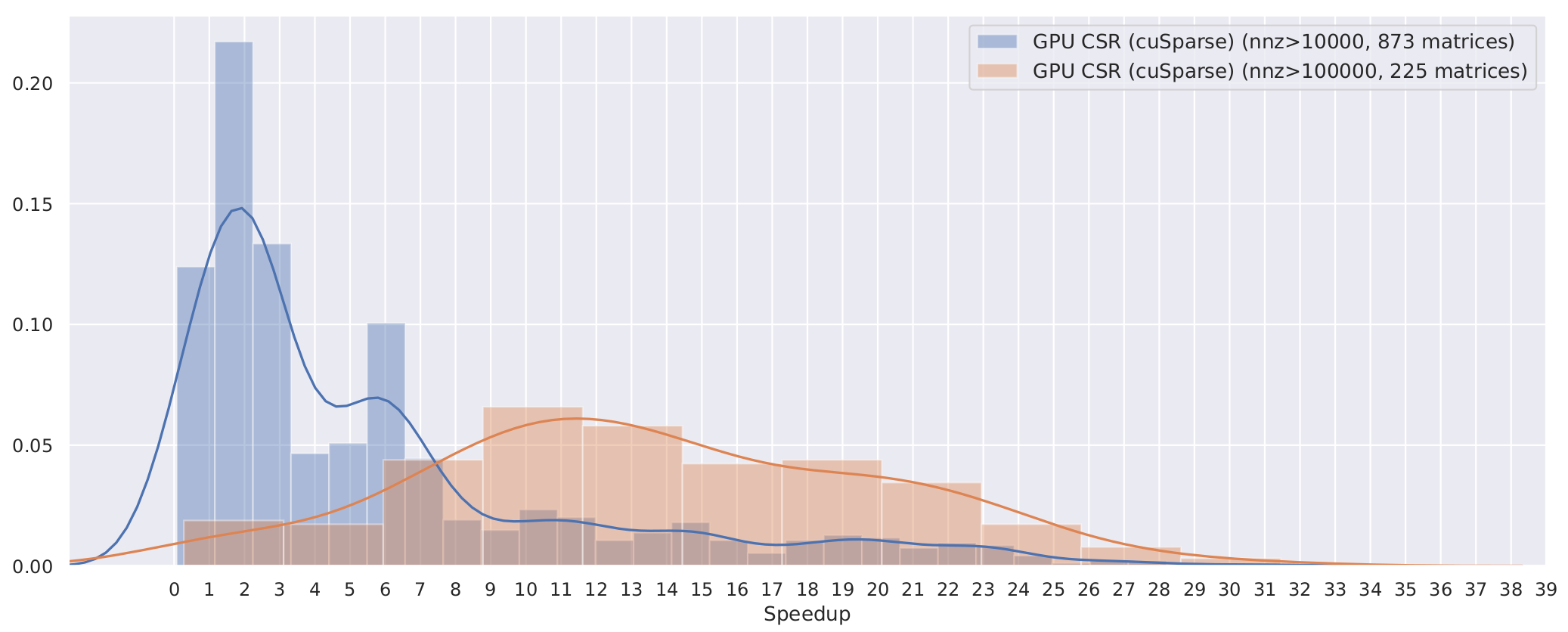
Sparse Matrix Vector Multiplication With Cuda By Georgii Evtushenko Analytics Vidhya Medium

Pin On Useful Links

Sparse Matrix Vector Multiplication An Overview Sciencedirect Topics

1 Sequential Algorithm For Sparse Matrix Vector Multiplication Where Download Scientific Diagram
Sparse Matrix Vector Multiplication With Cuda By Georgii Evtushenko Analytics Vidhya Medium

Gpu Accelerated Sparse Matrix Vector Multiplication And Sparse Matrix Transpose Vector Multiplication Tao 2015 Concurrency And Computation Practice And Experience Wiley Online Library

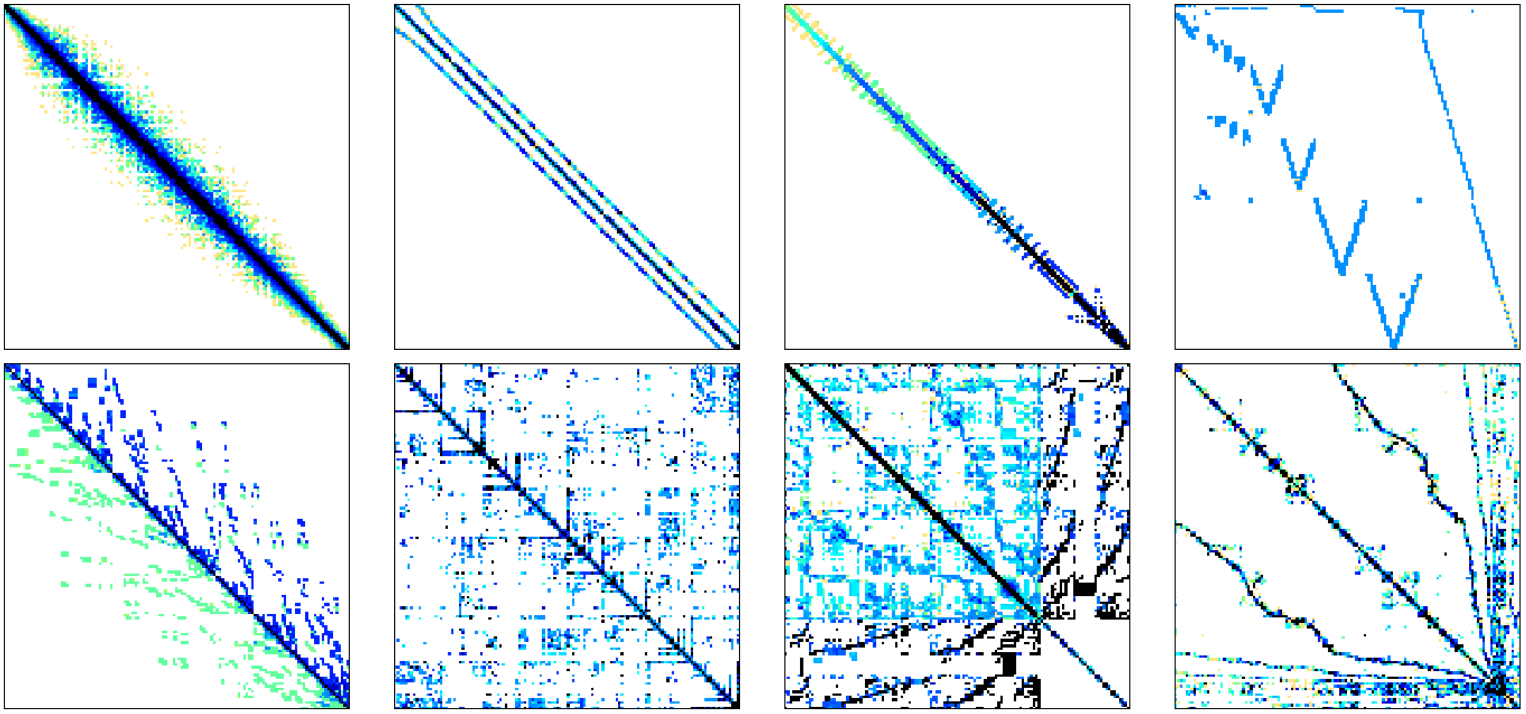
Sparse Matrix Vector Multiplication And Csr Sparse Matrix Storage Format Download Scientific Diagram

Sparse Matrix Vector Multiplication With Cuda By Georgii Evtushenko Analytics Vidhya Medium

Matrix Vector Multiplication In Cuda Benchmarking Performance Stack Overflow

Support Vector Regression In R Tutoral Regression Data Science Data Scientist