Matrix Multiplication Python Cuda
Float Belement b k MATRIX_SIZEs tx. Anpones 20150000dtypenpfloat32 Bnpones 1307250000dtypenpfloat32 Cnpones 20307250000dtypenpfloat32 I skipped one dimension in A and B because it is not necessary for the computation.

Cuda Python Matrix Multiplication Programmer Sought
The values of Matrix B.

Matrix multiplication python cuda. Matrix Multiplication in CUDA by using TILES. Execute the following cell to write our naive matrix multiplication kernel to a file name matmul_naivecu by pressing shiftenter. Y block_size_y threadIdx.
Matrix multiplication in CUDA this is a toy program for learning CUDA some functions are reusable for other purposes. In order to resolve any confusion this is actually a 3D matrix by 3D matrix multiplication. C ty MATRIX_SIZEs tx Pvalue.
Pvalue Aelement Belement. The input follows this pattern. Assume A is a p w matrix and B is a w q matrix So C will be p q matrix.
For int k 0. Matrix multiplication is simple. Matrix multiplication between a IxJ matrix d_M and JxK matrix d_N produces a matrix d_P with dimensions IxK.
About Press Copyright Contact us Creators Advertise Developers Terms Privacy Policy Safety How YouTube works Test new features Press Copyright Contact us Creators. Int y blockIdx. The number of columns of Matrix A.
The values of Matrix A. Python matmatmuloclpy matrix A. Implementing in CUDA We now turn to the subject of implementing matrix multiplication on a CUDA-enabled graphicscard.
Writefile matmul_naivecu define WIDTH 4096 __global__ void matmul_kernel float C float A float B int x blockIdx. Float Aelement a ty MATRIX_SIZEs k. Note that the evaluation of C should be put in the conditional loop to guarentee.
For the algorithm you can take a look at Bottlenecks. X block_size_x threadIdx. Matrix matrix multiplication Our running example will be the multiplication of two matrices.
In this video we look at writing a simple matrix multiplication kernel from scratch in CUDAFor code samples. I understand that GPUs are only faster with matrix multiplication for very large matrices but I wanted to use small examples to be able to check whether the answer is correct before applying it to actual data. The formula used to calculate elements of d_P is d_Pxy 𝝨.
21 The CUDA Programming Model. The number of lines of Matrix B. The number of columns of Matrix B.
Lets say we want to multiply matrix A with matrix B to compute matrix C. The number of lines of Matrix A. Test results following tests were carried out on a Tesla M2075 card lzhengchunclus10 liu aout.
Time elapsed on matrix multiplication of 1024x1024. Leave the values in this cell alone M 128 N 32 Input vectors of MxN and NxM dimensions a nparangeMNreshapeMNastypenpint32 b nparangeMNreshapeNMastypenpint32 c npzerosM Mastypenpint32 d_a cudato_devicea d_b cudato_deviceb d_c cudato_devicec NxN threads per block in 2 dimensions block_size NN MxMNxN blocks per grid in 2 dimensions grid_size intMNintMN import numpy as np from numba import cuda types ucuda. Please type in m n and k.
Cudajit functions matmul and fast_matmul are copied from the matrix multiplication code in Numba CUDA example. Function matmul_gu3 is a guvectorize function its content is exactly the same as cudajit functions matmul and the target argument is set as cuda. Y_d z_d z_h z_dcopy_to_host printz_h printemail protected_h cuda-memcheck python t49py CUDA-MEMCHECK.
Float sum 00. TILED Matrix Multiplication in CUDA by using Shared Constant Memory. The above sequence is arranged in the increasing order of efficiency performance 1st being the slowest and 5th is the most efficient fastest.
We will begin with a description of programming in CUDA then implement matrix mul-tiplication and then implement it in such a way that we take advantage of the faster sharedmemory on the GPU. Matrix multiplication Write a kernel where each thread calculates one element of the result matrix C A B where A and B are matrices. Matrix Multiplication using GPU CUDA Cuda Matrix Implementation using Global and Shared memory.
A typical approach to this will be to create three arrays on CPU the host in CUDA terminology initialize them copy the arrays on GPU the device on CUDA terminology do the actual matrix multiplication on GPU and finally copy the result on CPU.

Cuda Python Matrix Multiplication Programmer Sought

How To Increase Speed Transfer Of Matrices Gpu Cpu For Matrix Multiplication It Is The Limiting Factor Cuda Programming And Performance Nvidia Developer Forums

Thread Organization And Matrix Multiplication Mcs572 0 6 2 Documentation
Http Games Cmm Uchile Cl Media Uploads Courses 2016 Informe Garrido Mario Pdf

Thread Organization And Matrix Multiplication Mcs572 0 6 2 Documentation

Thread Organization And Matrix Multiplication Mcs572 0 6 2 Documentation

Thread Organization And Matrix Multiplication Mcs572 0 6 2 Documentation

Pin On Useful Links
A Short Notice On Performing Matrix Multiplications In Pycuda By Vitality Learning Medium
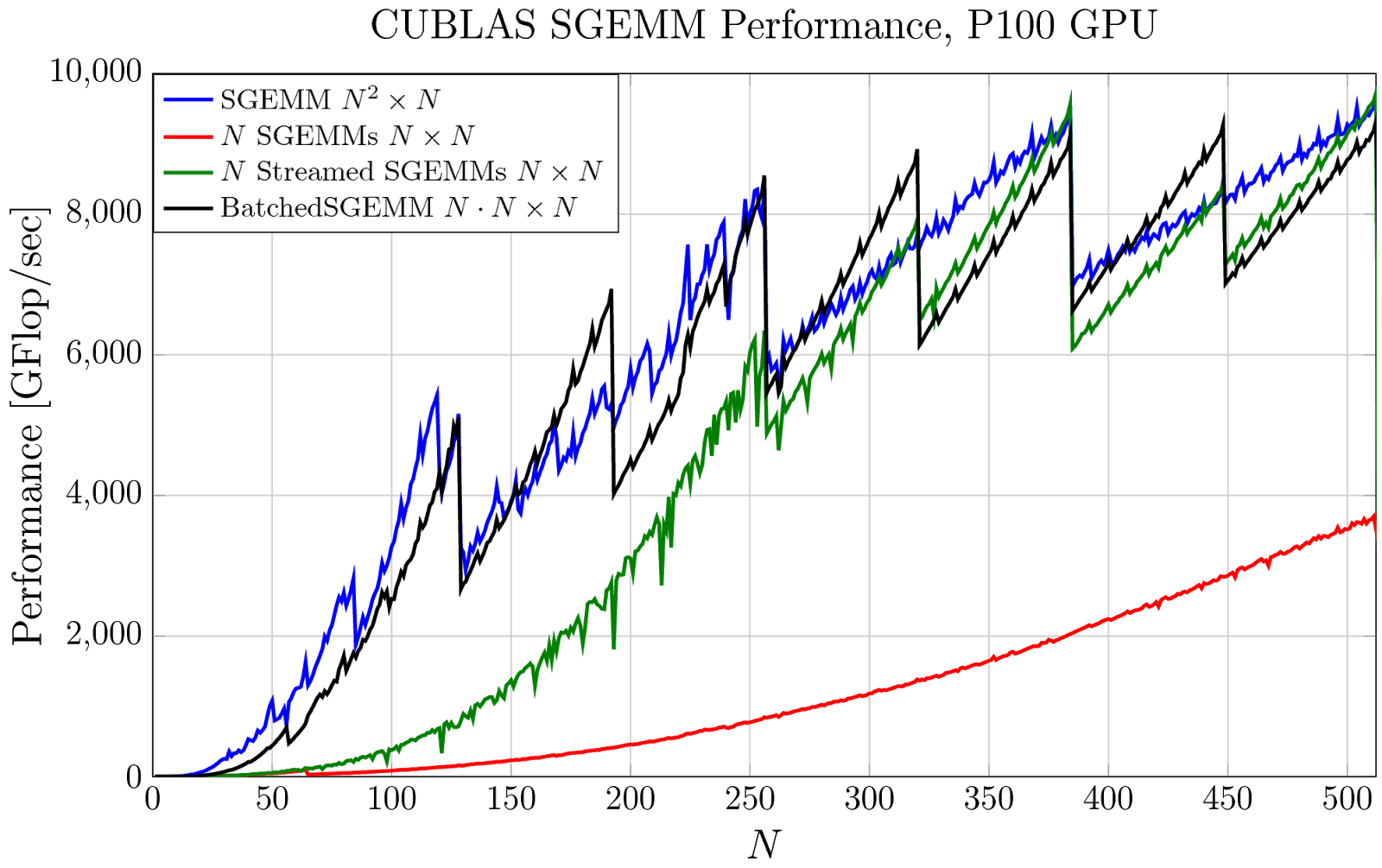
Pro Tip Cublas Strided Batched Matrix Multiply Nvidia Developer Blog

Pin On Useful Links
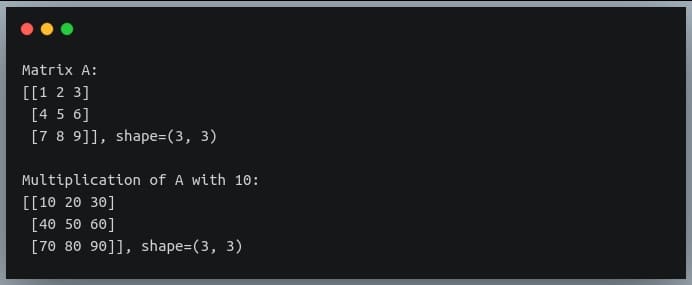
20 Examples For Numpy Matrix Multiplication Like Geeks
Pycuda Series 2 A Simple Matrix Algebra And Speed Test Liang Xu
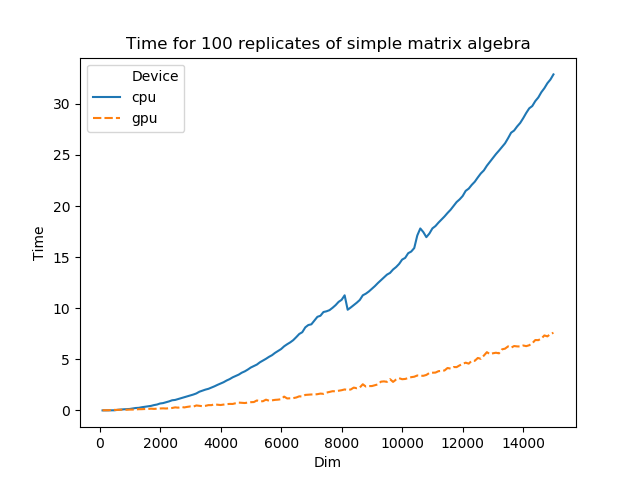
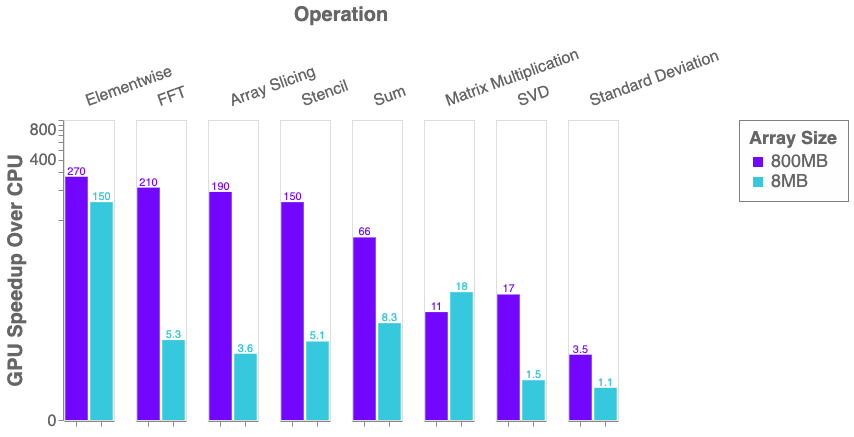
Python Performance And Gpus A Status Update For Using Gpu By Matthew Rocklin Towards Data Science

Thread Organization And Matrix Multiplication Mcs572 0 6 2 Documentation

Thread Organization And Matrix Multiplication Mcs572 0 6 2 Documentation
Parallel Computing For Data Science With Examples In R C And Cuda Norman Matloff Obuchenie Programmirovanie Shpargalki

Gpu Programming And Py Cuda Brian Gregor Shuai
Https Arxiv Org Pdf 1901 03771